
STRG’s CEO, Jürgen Schmidt, talks about the impact of artificial intelligence on digital media
On March 2, 2021, STRG CEO Jürgen Schmidt gave a keynote address to the JETZT summit, an annual conference for digital marketing professionals in Austria and across the DACH region. Due to the pandemic, the conference was held entirely online, yet the virtual attendees were no less impressed by Schmidt’s presentation, judging from their enthusiastic chat-comments.
Schmidt’s natural talent for relating complex ideas in a fun, easy-to-understand manner was on full display. His talk, entitled “Data-Driven Publishing Reloaded – The Matrix is Real”, covered a lot of MarTech’s hottest topics – natural language processing, machine learning, semantic content analysis, behavioural economics, how to improve data quality, and several others.
A central theme throughout his talk was how to reconcile the irrationality of human intelligence with the rationality of artificial intelligence. By citing entertaining examples of how this can lead to poor, unintended results – e.g., a Berlin-based artist who was able to trick GoogleMaps into thinking there was a traffic jam when he walked down a street carrying 100 Android phones – Schmidt criticized artificial intelligence based upon a “supervised” learning model (i.e., when it is given human instruction in advance).
Schmidt explained how today’s massive uptake in computing power and sophisticated programming offers an alternative, “unsupervised” machine-learning model, where computers can analyse and classify data without being given restrictive rules up front. However, such a model requires huge amounts of data, which gives an advantage to large English-language markets like the USA, but is more limited in Europe and Asia.
A third model, “reinforcement” learning, resembles the age-old “carrot-and-stick” approach – learning through reward and punishment. Schmidt says that the Agent Smith character from The Matrix movies exemplifies how such a reinforcement-based virtual machine is able to create strategy autonomously, with little to no advance instruction, just by learning from its own behaviour.
“A reinforcement learning model doesn’t need the enormous data set because even a small amount of data from within a single portal can be extrapolated using data-simulation.”
According to Schmidt, a reinforcement learning model doesn’t need the enormous data set that an unsupervised one requires, because even a small amount of user-journey data from within a single portal can be extrapolated using data-simulation algorithms that learn autonomously by trial and error. This can yield more intelligent analyses by avoiding the false feedback loop that can arise with insufficient data – for example, when portals use poor click-rate data to promote “engaging” content, which in turn gets clicked more often, regardless of its actual interest to the user.
Interviewed before his keynote address by Internet World Austria, Schmidt said, “If one compares the real results achieved from today’s data availability, such as click rates, with older methods, one can’t really see very much improvement, because nobody bothers to consider the base quality of the data – its accuracy regarding content.” He added, “ Just because someone clicked on a link somewhere, traditional tracking analysis will only tell [content publishers] to focus on the same related issues and topics”.
Schmidt lamented that “We in the field of marketing tech tend to lag behind other branches, especially if you compare our methods with advanced technologies such as driverless autos, image-recognition and ‘deep-fake’ videos. It is therefore fascinating to study developments in other areas and learn how to apply them to marketing tech. This is how [STRG] got the idea of using data simulation – by looking at what experimental methods Tesla and robotics are using.”
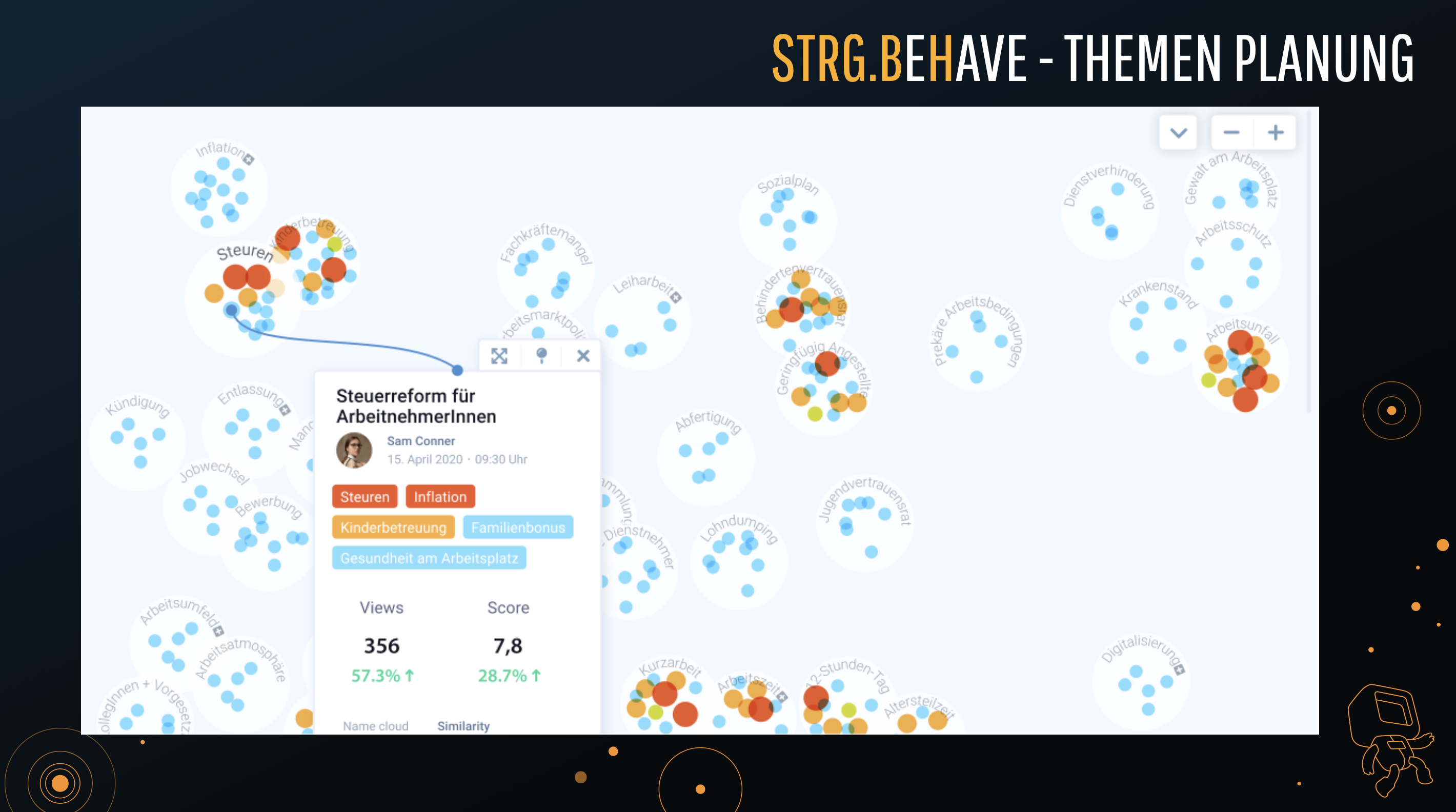
The use of artificial intelligence for digital media opens up many possibilities that will improve portals – especially in the area of e-commerce and digital publishing. STRG develops content-management systems using a proprietary STRG.BeHave AI technology to parse the analytics in completely novel ways, like using principles of behavioural economics.
“The possibilities of data simulation open up entirely new applications.With low traffic volume, analysing tracking data isn’t very helpful.”
As Schmidt told IWA: “We are currently researching advantages that can be gained by using data simulations…. In data-driven publishing, the key is data quality, which is rarely discussed. Even AI can’t turn bad data into good solutions.” Garbage in, garbage out will always be the rule. “The possibilities of data simulation open up entirely new applications….With low traffic volume, analysing tracking data isn’t very helpful. AI needs a certain quantity and breadth of data to be reliable.”
Schmidt also notes that in Europe, data protection is taken seriously and he thinks this is the right thing to do. The regulatory environment is resulting in new innovations that will move the digital industries beyond today’s questionably effective user-consent / opt-out measures. It is becoming increasingly likely that third-party cookies will soon be replaced by technology like Federated Learning of Cohorts (FLoCs), where individual user data would be replaced by data sets from user groups for the sake of ad and content targeting. Google is currently exploring a “Privacy Sandbox” concept for phasing out third-party cookies and STRG is at the forefront of this movement to simplify marketing technology while protecting individual data privacy. Schmidt feels that “in the ‘cookieless’ future, much more high-quality data will become available, which will benefit even smaller portals.” In concluding his JETZT keynote address, Schmidt recommended investment in marketing technologies, especially artificial intelligence, which are not as costly as one might think.
To learn more about the technology we use to enhance your digital publishing contact Jürgen Schmidt or Michael Dosser
- Call STRG's CEO Jürgen, or write a mail juergen.schmidt@strg.at Mobile: +43 699 1 7777 165



