
Unsere Fachkompetenz ist unser Produkt
Es ist ein Expertenwissen, das aus intensiver Forschung sowie aus menschlichem und maschinellem Lernen stammt. Wir bezeichnen STRG.CMS oder STRG.BeHave vielleicht als unsere „Produkte“ und nennen einige unserer agilen Mitarbeiter „Product Owner“, aber in Wirklichkeit produziert STRG nichts, was in eine eingeschweißte Verpackung gesteckt und über den Ladentisch verkauft werden kann. Wir bieten weder herunterladbare Anwendungen noch White-Label-Webdienste an. Wir veröffentlichen auch keine Preisliste mit unseren Standardgebühren oder Paketpreisen.
Was tun wir also? Eine $ch#!+Menge an Forschung, das ist es! Unsere Forschung hat nicht das Ziel, ein fertiges Produkt zu schaffen. Sie führt vielmehr zu sich ständig weiterentwickelnden Instrumenten, mit denen die talentierten Teams von STRG die Probleme der Kunden lösen.
STRG ist ein technologieorientiertes Unternehmen. Wann immer wir auf eine Herausforderung stoßen, die mit der aktuellen Technologie nicht gelöst werden kann, schalten wir in den Forschungsmodus.
Vom Konzept zu praktischen Werkzeugen
Eine der ersten Anwendungen unserer Forschungsarbeit war STRG.CMS, eines der ersten Content-Management-Systeme, das semantische Analyseverfahren einsetzte. Die vorhandenen Tools zur Erstellung personalisierter Nachrichteninhalte belasteten die Redakteure jedoch mit der Aufgabe, Inhalte zu markieren, zu kategorisieren und zu beschriften. Wir sahen dies als eine Herausforderung, die mit Methoden des maschinellen Lernens gelöst werden konnte.
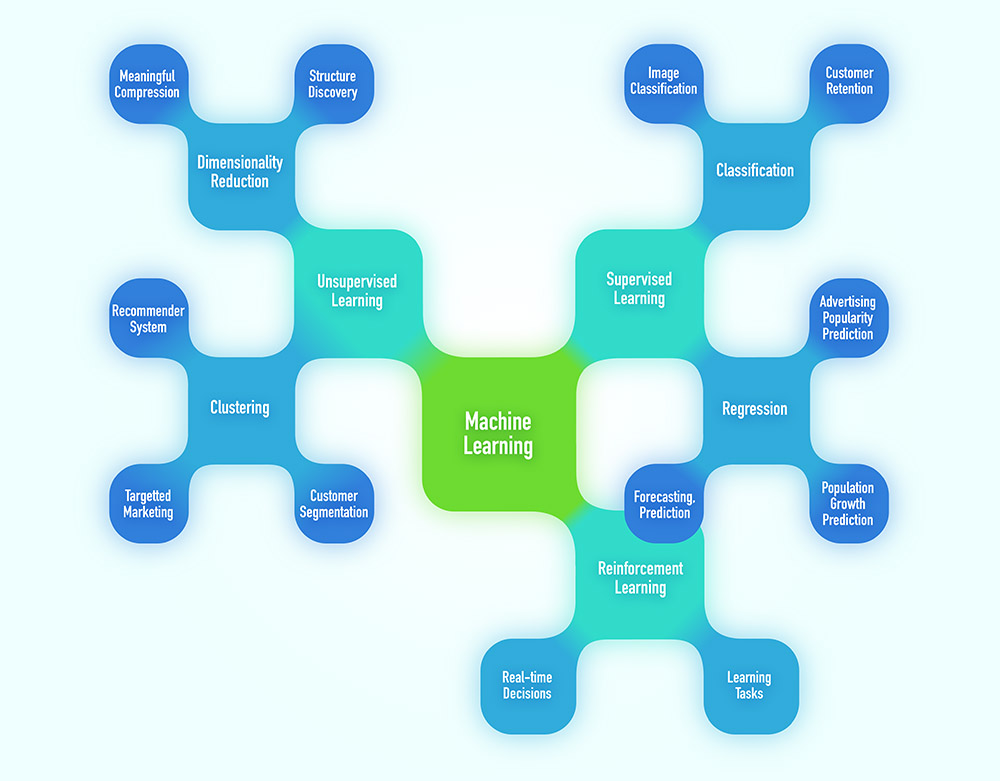
Kurz nach der Veröffentlichung von Google’s TensorFlow (2016) kam STRG’s CEO Jürgen Schmidt auf die Idee, ein Forschungsprojekt zu initiieren, um tiefer in den Bereich der semantischen Analyse einzudringen, einschließlich Natural Language Processing (NLP), Worteinbettungen und Methoden des überwachten Lernens. Ursprünglich sollte die Forschung in ein Produkt münden, zumindest eines für den internen Gebrauch. Im Jahr 2018 wurde von der Österreichischen Forschungsförderungsgesellschaft (FFG) eine optimale Unterstützung gewährt – die weder streng auf die Forschung noch auf die Produktentwicklung ausgerichtet war. Zwei Jahre lang wurde geforscht und das Ergebnis war STRG.BeHave.
“Anstatt ein marktfähiges Produkt für andere zu entwickeln, haben wir eigene Toolkits entwickelt, die wir intern zur Entwicklung von Anwendungen oder E-Commerce-Portalen nutzen“, sagt Eugen Lindorfer, seit acht Jahren Product Owner bei STRG. „Wir haben festgestellt, dass wir kein Produktunternehmen sind, sondern ein Projektunternehmen. Alle sagen, dass man nicht beides machen kann, weil beides eine völlig andere Organisationsstruktur und Denkweise erfordert. Als wir unsere Sichtweise von der eines Produktentwicklers zu der eines problemlösenden Projektunternehmens änderten, nahm unser Geschäft richtig Fahrt auf.”
“Wir sind kein Produktunternehmen, sondern ein Projektunternehmen. Alle sagen, dass man nicht beides machen kann, weil beides eine völlig andere Organisationsstruktur und Denkweise erfordert.”
Während andere Tech-Unternehmer immer auf der Suche nach der nächsten Killer-App sind, hat STRG der Versuchung widerstanden, Plug-and-Play-Softwarelösungen zu entwickeln, und stattdessen seine forschungsbasierte Expertise und sein Know-how vermarktet. „Natürlich hätten wir etwas Ähnliches wie Outbrain entwickeln können“, sagt Lindorfer, „aber das ist nur ein kleiner Teil dessen, was man mit BeHave machen kann. Wenn wir BeHave als Produkt auf den Markt bringen würden, würden potenzielle Kunden es nur mit Outbrain vergleichen, was ich als ineffektiv ansehe, besonders wenn es darum geht, Kunden zu ermöglichen, ihre Inhalte zu monetarisieren. Außerdem glaube ich nicht, dass wir mit einem solchen Produkt viel Geld verdienen würden.”
Navigation durch Archivinhalte
Einer der ersten Kunden, der von der FFG-geförderten Forschung zu BeHave profitierte, war die österreichische Wochenzeitung „Die Furche“. Während wir sie bei der Gestaltung und Entwicklung ihres Online-Portals unterstützten, entdeckten wir, dass wir das semantische Natural Language Processing (NLP) Toolkit von BeHave einsetzen können, um ihre umfangreichen Archivinhalte, die bis zu ihrer Gründung im Jahr 1945 zurückreichen, zu organisieren und anzuzeigen.
„Wir haben eine Zeitleistenfunktion entwickelt, die sie ‚Navigator‘ nannten“, sagt Lindorfer. „Sie nutzt eine KI-gestützte semantische Analyse, um sowohl aktuelle digitale Inhalte als auch ältere, digital gescannte Inhalte automatisch zu kategorisieren und zu kennzeichnen – sogar die Gedichte, die seit über 50 Jahren nicht mehr veröffentlicht werden.“ Die elegante Timeline-Slider-Funktion verbessert das Leseerlebnis, indem sie zeitgenössische Inhalte automatisch in einen historischen Kontext stellt.
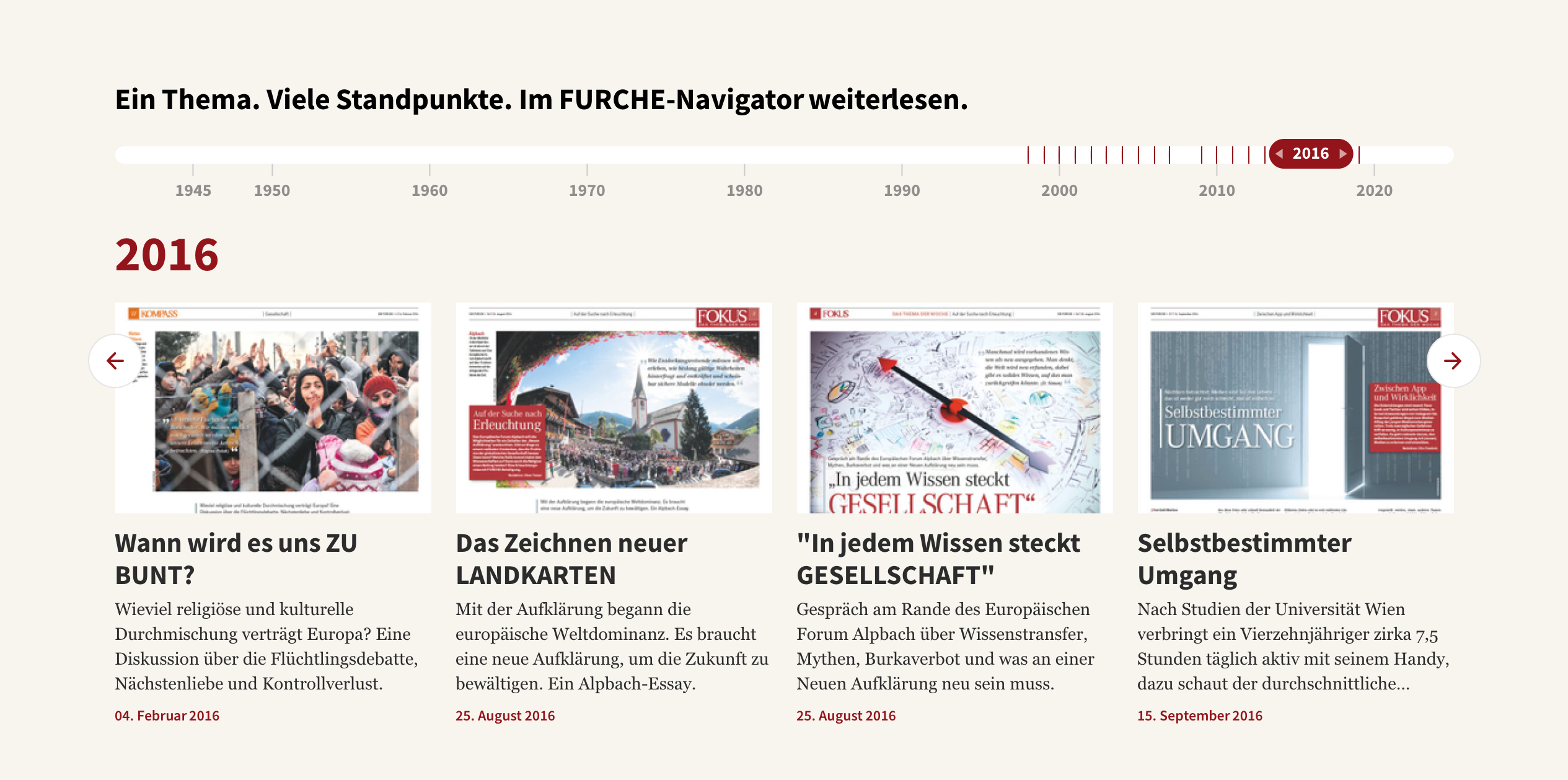
Die Furche hat ihre eigene begabte IT-Abteilung, die sich vielleicht für eine Plug-and-Play-App entschieden hätte, um die Anzeige verwandter Inhalte zu ermöglichen, aber dies hätte unzählige Stunden redaktionellen Aufwands erfordert, um ihre Archive manuell zu beschriften und zu kategorisieren. „Wir bekamen den Auftrag nicht, weil BeHave ein Produkt von der Stange war, das wir ihnen verkaufen konnten“, glaubt Lindorfer, „sondern weil es ein Tool war, mit dem wir ihre Technologie auf ihre spezifischen Anforderungen zuschneiden konnten.“
Über die Nachrichten hinaus
Dank der Forschung und Entwicklung von STRG.CMS und BeHave konnte sich STRG einen guten Ruf in der Zusammenarbeit mit Kunden aus dem Bereich der digitalen Nachrichtenmedien sichern. Als wir BeHave für dieses Marktsegment recherchierten, erkannten wir, dass die verschiedenen Toolkits und Pakete auch in anderen Bereichen, wie dem ÖAMTC, eingesetzt werden können.
„Wenn wir recherchieren, finden wir manchmal Lösungen für Probleme, die wir gar nicht zu lösen versuchten“, erklärt Lindorfer. „Dadurch, dass wir uns nicht auf ein bestimmtes Produkt als Ergebnis konzentrieren, zieht unser Ruf als technologieorientierte Forscher die Aufmerksamkeit vieler Kunden aus verschiedenen Bereichen auf sich, die eine maßgeschneiderte Lösung für ihr Portal wünschen.”
“Dadurch, dass wir uns nicht auf ein bestimmtes Produkt als Ergebnis konzentrieren, zieht unser Ruf als technologieorientierte Forscher die Aufmerksamkeit vieler Kunden aus verschiedenen Bereichen auf sich, die eine maßgeschneiderte Lösung für ihr Portal wünschen.”
Agenten des Wandels
Während die Forschung an BeHave weiterläuft, hat sich daraus ein neues, von der FFG finanziertes Forschungsprojekt entwickelt, das wir „STRG.Agents“ nennen. Die Idee entstand (wie so oft) aus dem Versuch, ein Problem zu lösen. Einer der größten österreichischen Versandhändler/E-Commerce-Händler wollte die Personalisierungsfunktionen seiner Website mit der Art von Produktempfehlungen und automatisierten Benutzeroberflächentechnologien verbessern, wie sie von so vielen E-Commerce-Portalen, einschließlich Amazon, mit gemischten Ergebnissen verwendet werden (haben Sie sich jemals gefragt, warum Sie Produktempfehlungen für Kühlschränke erhalten, obwohl Sie gerade einen neuen gekauft haben?)
„Wir wollten dies mit der semantischen Analysemethodik, die wir mit BeHave entwickelt haben, verbessern“, erinnert sich Lindorfer. „Wir haben versucht, mit BeHave-Algorithmen kurze Produktbeschreibungen semantisch zu analysieren und mit stark strukturierten Produktdaten in Beziehung zu setzen. Zuerst hat das nicht so gut funktioniert, aber dann haben wir herausgefunden, warum. Die Seite war zwar in Österreich sehr beliebt, hatte aber einfach nicht das Verkehrsaufkommen, um einen geeigneten Datensatz zu erzeugen. Was konnten wir dagegen tun? Wie könnten wir Erkenntnisse über Websites gewinnen, die es gar nicht gibt? Diese beiden Fragen waren der Ansporn für unser nächstes Forschungsprojekt.”
Nach vielen Diskussionen über Wein und Kaffee wurde STRG.Agents in diesem Jahr auf die Beine gestellt. Der „Aha!“-Moment kam, als wir erkannten, dass wir durch die Analyse des Nutzerverhaltens auf Nachrichtenportalen Erkenntnisse für E-Commerce-Plattformen gewinnen können – und zwar nicht semantisch, sondern darüber, wie Nutzer mit der Seite umgehen. Allerdings verbieten die strengen GDPR-Datenschutzbestimmungen die Verwendung individueller Nutzerdaten für unbeabsichtigte Zwecke. Dennoch sagt Lindorfer: „Wir haben erkannt, dass es möglich ist, den Besuch der Website mit Hilfe von virtuellen Nutzern zu simulieren, die wir ‚Agenten‘ nennen.“ Agenten ist ein Begriff aus dem Bereich des Verstärkungslernens (Reinforcement Learning), einer KI-Technologie, die es Maschinen ermöglicht, in jeder Umgebung autonom zu lernen, ähnlich wie ein Welpe neue Tricks lernt – eine Kombination aus Aktionen, Belohnungen und Beobachtung.
“Wir haben festgestellt, dass es möglich ist, den Besuch einer Website mit virtuellen ‚Agenten‘ zu simulieren, was den Mangel an aussagekräftigen realen Nutzerdaten von kleineren Webportalen ausgleichen oder sogar den Verkehr für noch nicht erstellte Websites vorhersagen könnte.”

Lindorfer und die Datenwissenschaftlerin der STRG sind der Ansicht, dass Webportale als gerichteter Graph modelliert werden können und die Benutzerinteraktionen in einem Webportal als Markov-Belohnungsprozess dargestellt werden können, der Zustände (d.h. welche Webseite man gerade durchsucht), Aktionen (wohin scrolle ich oder klicke ich) und Belohnungen (basierend auf einem begrenzten Datensatz von realen Benutzerumwandlungen) enthält, um die Wahrscheinlichkeiten für den Übergang von einem Zustand zum nächsten zu bestimmen. Die Durchführung einer solchen Simulation für virtuelle Benutzer könnte den Mangel an aussagekräftigen realen Benutzerdaten von kleineren Webportalen ausgleichen oder sogar den Verkehr für noch nicht erstellte Webseiten vorhersagen.
„Wir müssen unsere Agents-Forschung noch auf konkrete Anwendungen übertragen“, räumt Lindorfer ein, „aber wir planen, sie für die Optimierung von E-Commerce-Portalen zu nutzen, nicht nur um Produktempfehlungen zu verbessern, sondern auch um die gesamte Benutzeroberfläche zu verbessern, was die Platzierung von Links angeht, wie groß sie sein sollten und so weiter.“
Das Forschungsprojekt ist in mehrere Arbeitspakete gegliedert und wird von der FFG für ein Jahr gefördert. „Letztendlich wollen wir in der Lage sein, eine grafische Darstellung eines Webportals automatisch zu erstellen, indem wir einfach eine URL eingeben“, träumt Lindorfer. „Wir wollen aber auch Seiten modellieren, die es noch nicht gibt, und ein Drag-and-Drop-Backoffice-System schaffen, um Lernstrukturen anzupassen und Einblicke in die Ergebnisse von Agentensimulationen zu erhalten.“
Die Früchte unserer Forschung ernten
Natürlich kann die sich ständig weiterentwickelnde Technologie jedes langfristige Entwicklungsprojekt überflüssig machen, bevor es abgeschlossen ist, so dass die Forschung von Agents spontan angewendet wird. Der Vorstandsvorsitzende der STRG, Jürgen Schmidt, sagt: „Man kann nicht warten, bis etwas vollständig ausgereift ist, bevor man es auf den Markt bringt. Agents wird mindestens zwei Jahre Entwicklungszeit benötigen, aber bereits 2022 werden wir damit beginnen, einige Module auf unsere laufenden Projekte anzuwenden.”
Die Forschung von STRG kann sich nicht nur auf kurzfristige Ziele konzentrieren. „Ein Unternehmen, das eine Software zur automatischen Klassifizierung von Bildern suchte, wandte sich wegen einer maßgeschneiderten Lösung an uns“, erinnert sich Lindorfer, „aber bevor wir den Vertrag abschließen konnten, fanden sie eine neue Open-Source-Lösung von der Stange, die ihren Anforderungen perfekt entsprach.“
Obwohl Lindorfer es für unwahrscheinlich hält, dass Reinforcement Learning in absehbarer Zeit durch etwas anderes ersetzt wird, können weder er noch die Datenwissenschaftler von STRG immer die Zeit aufbringen, um mit allen aktuellen und zukünftigen Entwicklungen Schritt zu halten. „In diesem Bereich sind die Algorithmen und Bibliotheken ständig im Fluss. Deshalb haben wir eine Partnerschaft mit der österreichischen Fachhochschule St. Pölten. Diese jungen Akademiker haben die Zeit, all diese superschlauen Konferenzen zu besuchen und uns auf dem neuesten Stand zu halten. Zum Beispiel verwenden wir normalerweise die Frameworks TensorFlow und PyTorch für die Implementierung von maschinellem Lernen, aber ein Forscher aus St. Pölten hat auf einer Konferenz erfahren, dass Google gerade das JAX-Framework veröffentlicht hat.“
Im Moment stellen Facebook und Google einige Softwarebibliotheken für das maschinelle Lernen als Open Source zur Verfügung. Aber wenn man ihnen erlaubt, den Markt zu monopolisieren, weiß man, dass sie ihn am Ende zu Geld machen werden. „Wir können diese Forschung nicht diesen großen Unternehmen überlassen“, warnt Lindorfer, „sonst werden wir zu abhängig von ihnen. Es geht ihnen nicht darum, die Welt zu verbessern, sondern darum, den Markt zu beherrschen und viel Geld zu verdienen“.
Indem wir uns auf die Zukunftsforschung statt auf die Produktentwicklung konzentrieren, können die Erkenntnisse, die STRG gewinnt, immer auf etwas völlig anderes als das ursprüngliche Ziel angewendet werden. Es wird nie eine vergebliche Mühe sein.
Wenn die Probleme kleinerer E-Commerce-Unternehmen mit Hilfe der Forschung von STRG.Agents gelöst werden können, könnte dieselbe Technologie möglicherweise auch zur Lösung größerer gesellschaftlicher Probleme wie saubere Energie und die globale Lieferkette eingesetzt werden und dazu beitragen, die Wettbewerbsbedingungen zwischen den globalen Handelsmonopolen und den lokalen KMU auszugleichen.
Wenn Sie wissen möchten, wie die STRG-Forschung Ihr bestehendes digitales Unternehmen unterstützen oder Ihr digitales Debüt planen kann, wenden Sie sich an uns!
- Call STRG's CEO Jürgen, or write a mail juergen.schmidt@strg.at Mobile: +43 699 1 7777 165



